©
©
|
|
© |
|
|

|
Business Tier Design ConsiderationsWhen developers apply the business tier and integration tier patterns that appear in the catalog in this book, there may be adjunct design issues about which they may be concerned. These issues relate to designing with patterns at a variety of levels, and they may affect numerous aspects of a system. We discuss these issues in this chapter. The discussions in this chapter simply describe each issue as a design issue that you should consider when implementing systems based on the J2EE pattern catalog. Using Session BeansSession beans are distributed business components with the following characteristics, per the EJB specification:
Note In this section, we use the term "workflow" in the context of EJB to represent the logic associated with the enterprise beans communication. For example, workflow encompasses how session bean A calls session bean B, then entity bean C. Session Bean-Stateless Versus StatefulSession beans come in two flavors-stateless and stateful. A stateless session bean does not hold any conversational state. Hence, once a client's method invocation on a stateless session beans is completed, the container is free to reuse that session bean instance for another client. This allows the container to maintain a pool of session beans and to reuse session beans among multiple clients. The container pools stateless session beans so that it can reuse them more efficiently by sharing them with multiple clients. The container returns a stateless session bean to the pool after the client completes its invocation. The container may allocate a different instance from the pool to subsequent client invocations. A stateful session bean holds conversational state. A stateful session bean may be pooled, but since the session bean is holding state on behalf of a client, the bean cannot simultaneously be shared with and handle requests from another client. The container does not pool stateful session beans in the same manner as it pools stateless session beans because stateful session beans hold client session state. Stateful session beans are allocated to a client and remain allocated to the client as long as the client session is active. Thus, stateful session beans need more resource overhead than stateless session beans, for the added advantage of maintaining conversational state. Many designers believe that using stateless session beans is a more viable session bean design strategy for scalable systems. This belief stems from building distributed object systems with older technologies, because without an inherent infrastructure to manage component life cycle, such systems rapidly lost scalability characteristics as resource demands increased. Scalability loss was due to the lack of component life cycle, causing the service to continue to consume resources as the number of clients and objects increased. An EJB container manages the life cycle of enterprise beans and is responsible for monitoring system resources to best manage enterprise bean instances. The container manages a pool of enterprise beans and brings enterprise beans in and out of memory (called activation and passivation, respectively) to optimize invocation and resource consumption. Scalability problems are typically due to the misapplication of stateful and stateless session beans. The choice of using stateful or stateless session beans must depend upon the business process being implemented. A business process that needs only one method call to complete the service is a non-conversational business process. Such processes are suitably implemented using a stateless session bean. A business process that needs multiple method calls to complete the service is a conversational business process. It is suitably implemented using a stateful session bean. However, some designers choose stateless session beans, hoping to increase scalability, and they may wrongly decide to model all business processes as stateless session beans. When using stateless session beans for conversational business processes, every method invocation requires the state to be passed by the client to the bean, reconstructed at the business tier, or retrieved from a persistent store. These techniques could result in reduced scalability due to the associated overheads in network traffic, reconstruction time, or access time respectively. Session Beans as Business-Tier FacadesIn our patterns in the J2EE Pattern Catalog and best practices, one application of session beans is to use them as facades to the business tier. Session bean facades, or simply session facades, can be viewed as a coarse-grained controller layer for the business tier. Clients of the session beans are typically Business Delegates.
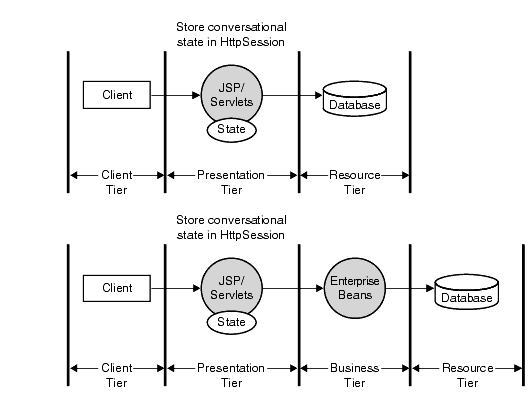
Storing State on the Business TierSome design considerations for storing state on the Web server are discussed in "Session State in the Presentation Tier" on page 37. Here we continue that discussion to explore when it is appropriate to store state in a stateful session bean instead of in an HttpSession. One of the considerations is to determine what types of clients access the business services in your system. If the architecture is solely a Web-based application, where all the clients come through a Web server either via a servlet or a JSP, then conversational state may be maintained in an HttpSession in the Web tier. This scenario is shown in Figure 4.1.
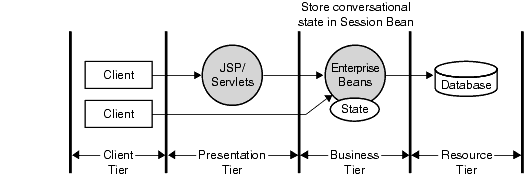
On the other hand, if your application supports various types of clients, including Web clients, Java applications, other applications, and even other enterprise beans, then conversational state may be maintained in the EJB layer using stateful session beans. This is shown in Figure 4.2.
We have presented some basic discussion on the subject of state management here and in the previous chapter (see "Session State on Client" on page 36). A full-scale discussion is outside the scope of this book, since the problem is multi-dimensional and depends very much on the deployment environment, including:
We touch on this issue because it is one that should be considered during development and deployment. Using Entity BeansUsing entity beans appropriately is a question of design heuristics, experience, need, and technology. Entity beans are best suited as coarse-grained business components. Entity beans are distributed objects and have the following characteristics, per the EJB specification:
Summarizing this definition, the appropriate use of an entity bean is as a distributed, shared, transactional, and persistent object. In addition, EJB containers provide other infrastructure necessary to support such system qualities as scalability, security, performance, clustering, and so forth. All together, this makes for a very reliable and robust platform to implement and deploy applications with distributed business components. Entity Bean Primary KeysEntity beans are uniquely identified by their primary keys. A primary key can be a simple key, made up of a single attribute, or it can be a composite key, made up of a group of attributes from the entity bean. For entity beans with a single-field primary key, where the primary key is a primitive type, it is possible to implement the entity bean without defining an explicit primary key class. The deployer can specify the primary key field in the deployment descriptor for the entity bean. However, when the primary key is a composite key, a separate class for the primary key must be specified. This class must be a simple Java class that implements the serializable interface with the attributes that define the composite key for the entity bean. The attribute names and types in the primary key class must match those in the entity bean, and also must be declared public in both the bean implementation class and primary key class. As a suggested best practice, the primary key class must implement the optional
java.lang.Object methods, such as
Business Logic in Entity BeansA common question in entity bean design is what kind of business logic it should contain. Some designers feel that entity beans should contain only persistence logic and simple methods to get and set data values. They feel that entity beans should not contain business logic, which is often misunderstood to mean that only code related to getting and setting data must be included in the entity bean. Business logic generally includes any logic associated with providing some service. For this discussion, consider business logic to include all logic related to processing, workflow, business rules, data, and so forth. The following is a list of sample questions to explore the possible results of adding business logic into an entity:
A "yes" answer to any of these questions helps identify whether introducing business logic into the entity bean can have an adverse impact. It is desirable to investigate the design to avoid inter-entity-bean dependencies as much as possible, since such dependences create overheads that may impede overall application performance. In general, the entity bean should contain business logic that is self-contained to manage its data and its dependent objects' data. Thus, it may be necessary to identify, extract, and move business logic that introduces entity-bean-to-entity-bean interaction from the entity bean into a session bean by applying the Session Facade pattern. The Composite Entity pattern and some of the refactorings discuss the issues related to entity bean design. If any workflow associated with multiple entity beans is identified, then such workflow can be suitably implemented in a session bean instead of in an entity bean. Such workflow can be consolidated into a session facade.
For bean-managed persistence in entity beans, data access code is best implemented outside entity beans.
Caching Enterprise Bean Remote References and HandlesWhen clients use an enterprise bean, they may need to cache some reference to an enterprise bean for future use. You will encounter this when using business delegates (see "Business Delegate" on page 248), where a delegate connects to a session bean and invokes the necessary business methods on the bean on behalf of the client. When the client uses the business delegate for the first time, the delegate needs to perform a lookup using the EJB Home object to obtain a remote reference to the session bean. For subsequent requests, the business delegate can avoid lookups by caching a remote reference or its handle as necessary. The EJB Home handle can also be cached to avoid an additional Java Naming and Directory Interface (JNDI) lookup for the enterprise bean home. For more details on using an EJB Handle or the EJB Home Handle, please refer to the current EJB specification. |
||||||||
| © 2001, Core J2EE Patterns, All Rights Reserved. |